

Eighty percent of data center failures can be prevented through proper data center maintenance. While most administrators address problems only once an outage occurs, a truly professional approach is built on three pillars: system redundancy, continuous monitoring, and regular inspections. We have prepared a practical checklist that shows exactly what to do to ensure stable operations without unpleasant surprises.
The following lines are not a theoretical exercise but the result of analyzing hundreds of real-world failures. Each checklist item is based on specific cases where properly implemented preventive measures saved operations before irreversible damage occurred.
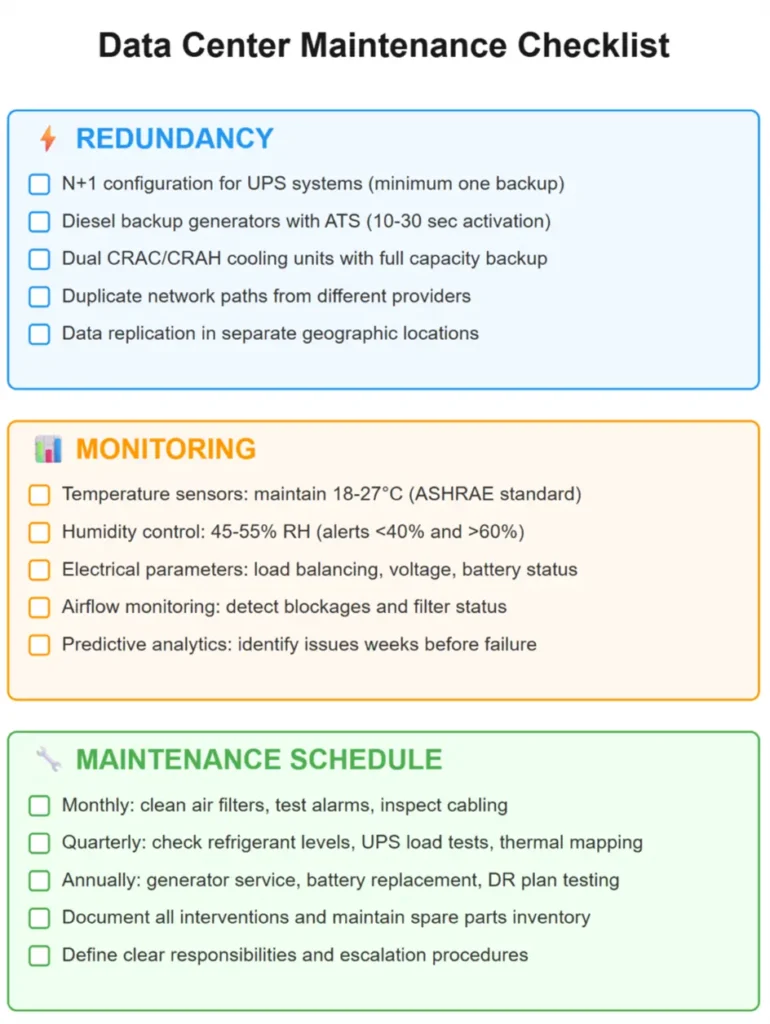
Redundancy Is the First Pillar of Effective Data Center Maintenance
A data center without redundancy is like a bridge supported by a single pillar—it works perfectly until something goes wrong. Data center redundancy means having backup systems for all critical components and forms the foundation of professional data center maintenance.
An N+1 configuration means at least one additional backup component. If you need three UPS units, deploy four. Diesel generators take over power delivery within 10–30 seconds, while an automatic transfer switch (ATS) shifts the load without interruption. Systematic monitoring of warning signals can detect an impending failure before an outage occurs.
Apply the same redundancy philosophy to other elements as well:
- two or more CRAC/CRAH units share the load, with each capable of handling full capacity if the others fail (redundant data center cooling),
- network infrastructure requires duplicate routers, switches, and connections from different providers,
- storage systems replicate data in at least two copies, ideally in geographically separate locations.
Continuous Monitoring as Part of Preventive Data Center Maintenance
High-quality data center maintenance is built on continuous monitoring of all critical parameters. What should this look like in practice? Monitoring systems evaluate every anomaly in real time and trigger alerts before a minor issue escalates into a failure.
Sensors measure temperature at both the intake and exhaust of racks. ASHRAE recommends:
- Temperature:
- 18–27°C (64.4–80.6°F),
- optimal range 20–24°C (68–75.2°F),
- overheating above 28°C (above 82.4°F) triggers warnings.
- Humidity:
- optimal range 45–55%,
- below 40% increases the risk of electrostatic discharge,
- above 60% leads to condensation.
Systems also track electrical parameters, circuit loads, and UPS battery status. Regular load tests verify that backup systems are functioning correctly. Airflow monitoring detects clogged filters or blocked ventilation before cooling performance drops.
Predictive analytics analyzes trends and forecasts failures. Increased fan vibration or longer compressor duty cycles can signal impending failure weeks in advance—providing enough time to order spare parts and schedule replacement during planned maintenance instead of handling an emergency outage.
Preventive Data Center Maintenance—A Checklist of Regular Inspections
Do not wait for a failure. Create a schedule of preventive inspections and follow it consistently. Every system requires its own specific maintenance interval.
Monthly, you should:
- Inspect and clean air filters in cooling units—clogged filters can reduce performance by 30–50%.
- Test the functionality of alarms and notifications in the monitoring system.
- Visually inspect cabling, looking for cracked insulation or loose connectors.
- Verify available capacity on storage systems and the status of RAID arrays.
Quarterly, perform:
- Checks of refrigerant levels and compressor pressure in CRAC units.
- Load testing of UPS systems, including verification of battery runtime.
- An audit of physical security—locks, cameras, and access control systems.
- Thermal mapping of the entire data hall to identify emerging hot spots.
Annually, plan:
- Servicing of diesel generators, including oil changes and fuel filter inspections.
- Replacement of UPS batteries (typical lifespan is 3–5 years, but degradation starts earlier).
- Inspection of electrical switchboards and verification that all connections are properly tightened.
- A full test of the disaster recovery plan with an actual switchover to backup systems.
Documentation and Accountability in Data Center Maintenance
Record every intervention. Systematic documentation reveals failure patterns and helps identify problematic components before they cause an outage. Keep records of all inspections performed, parts replaced, measured values, and detected anomalies.
Clearly define who is responsible for each task. Data center maintenance most often fails where everyone assumes that “someone else” will handle the check. Assign specific individuals to specific areas and establish escalation procedures for critical situations.
Consider outsourcing specialized data center maintenance if you lack internal capacity or expertise. Certified third-party technicians often uncover issues that internal teams overlook due to “operational blindness.” Clearly define response times and penalties for non-compliance in the SLA.
When Prevention Is Not Enough
Even with perfect preventive measures, emergency situations can still occur. For these moments, you must have a disaster recovery plan in place that defines precise steps for each type of incident. Having the plan written down is not enough—test it regularly through simulated outages.
Keep up-to-date contact details for spare-part suppliers with guaranteed delivery times. Store critical components (drives, fans, and power supplies) directly in the data center. Every hour spent waiting for a replacement part can cost thousands to millions in downtime losses.
Also Read-Why is Student Interest in Tech High?

{kind=link}